# Mysql索引
# 索引
Mysql 中常见的索引类型有:
- 普通索引
- 唯一索引
- 全文索引
- 空间索引
Mysql 中索引的数据结构有:
B+Tree,存储引擎InnoDB和MyISAM都支持。因为我们一般都是使用存储引擎InnoDB和MyISAM,我们都是使用B+Tree数据结构的索引。HASH,存储引擎MEMORY支持,存储引擎InnoDB和MyISAM不能手动定义 HASH 索引。
因此,我们详细了解 B+Tree 就行了。
我们先来介绍一下两种索引的数据结构的区别,感受一些各自的使用场景。
# Hash 数据结构的索引
Hash 数据结构,我们可以理解为 Java 中的 Map,存储的都是 key-value 键值对的数据,但我们没有办法进行范围查找。但是它的等值查找比较快,时间复杂度 O(1)。
创建一张表,字段有 id 和 description,并且在 description 上添加 HASH 索引。存储引擎使用 MEMORY
DROP TABLE IF EXISTS `index_hash_test`;
CREATE TABLE `index_hash_test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`description` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `inx_descrption` (`description`(100)) USING HASH
) ENGINE=MEMORY AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC;
INSERT INTO `index_hash_test` VALUES (1, 'a');
INSERT INTO `index_hash_test` VALUES (3, 'b');
INSERT INTO `index_hash_test` VALUES (2, 'c');
INSERT INTO `index_hash_test` VALUES (4, 'd');
INSERT INTO `index_hash_test` VALUES (5, 'e');
# HASH 索引范围查找不生效
-- 查看执行计划看到,全表扫描,没有走索引
EXPLAIN SELECT * FROM index_hash_test WHERE description >= 'b'

# HASH 等值查找生效
EXPLAIN SELECT * FROM index_hash_test WHERE description = 'b'

# B+Tree 数据结构的索引
B+Tree 数据结构的索引是可以进行范围查询的。
DROP TABLE IF EXISTS `index_test`;
CREATE TABLE `index_test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`description` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `inx_descrption` (`description`)USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `index_test` VALUES (1, 'a');
INSERT INTO `index_test` VALUES (3, 'b');
INSERT INTO `index_test` VALUES (2, 'c');
INSERT INTO `index_test` VALUES (4, 'd');
INSERT INTO `index_test` VALUES (5, 'e');
在 B+Tree 数据结构的索引表上执行查询计划,可以看到在查询的时候,索引可以使用。
EXPLAIN SELECT * FROM index_test WHERE description >= 'b';
EXPLAIN SELECT * FROM index_test WHERE description > 'b';
EXPLAIN SELECT * FROM index_test WHERE description = 'b';
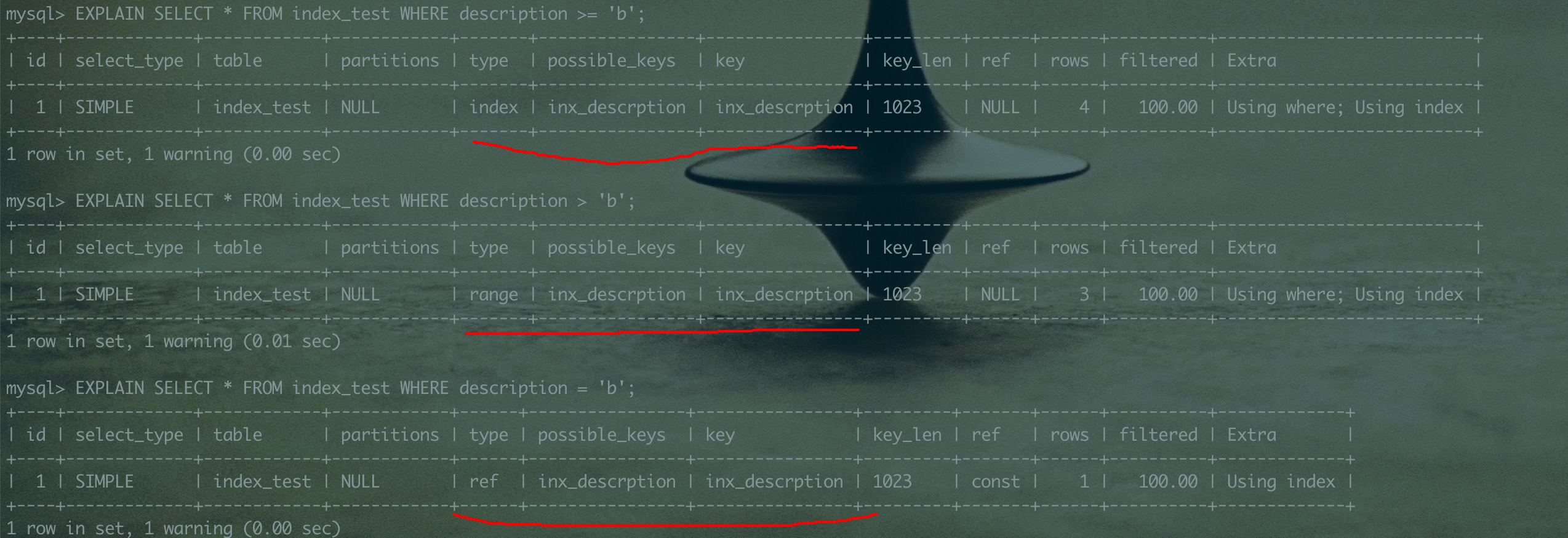
分别查看执行计划可以看到,等值查找和范围查找都使用到了索引,但是这三者性能上会有所差别 (以后会详细介绍这部分内容)。
# B+Tree 索引数据结构
实际开发中,我们使用的存储引擎是 InnoDB 和 MyISAM ,因此主要研究 B+Tree 索引
感兴趣的话可以在这个网站,看数据结构是怎样运行的。比如说 B+ 树插入、删除和查询
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html

相较于二叉树,B+ 树子节点会更多,树的高度会更低,在查找数据的时候,减少了遍历的次数以达到可以减少 Io 次数 (从磁盘加载数据到内存中)。
B+ 树相较于 B- 树,叶子节点是有序的,并且只有叶子节点会存数据。
比如查询大于 3 的数据的时候,找到了 3 直接遍历 3 上的链表就可以查询大于 3 的数据。
一个表上索引也不是越多越好,通常推荐不超过 5 个索引。因为我们修改数据的时候,数据库为了维护索引的数据结构也会产生计算和 io 从而影响数据的性能。当索引多的时候,数据量大的时候,这部分的影响就可以体现出来了。
当因为业务需要,添加的索引超过了 5 个,并且通过压测确定是索引过多影响了数据库的性能。可以考虑对表进行垂直拆分,将一部分业务字段拆分到另一个表中去。
# 索引相关名词
CREATE TABLE `my_test` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`age` varchar(200) DEFAULT NULL,
`phone` varchar(200) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `index_a_b` (`name`(20),`age`(5)) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `my_test` VALUES (1, 'a', '1');
INSERT INTO `my_test` VALUES (2, 'a', '2');
INSERT INTO `my_test` VALUES (3, 'a', '3');
INSERT INTO `my_test` VALUES (4, 'b', '1');
INSERT INTO `my_test` VALUES (5, 'b', '2');
关于索引的图只是示意性展示,重在理解。
# 聚簇索引
聚簇索引(也可以简单理解为主键)的叶子节点存的是整行数据,而非聚簇索引的叶子节点存的是索引数据和主键。

非叶子节点都是主键,叶子节点中既有主键对应的行数据。
当使用主键查询数据的时候,实际就是查询聚簇索引,然后从其中把数据读出来返回。
# 联合索引
联合索引:就是多个列组成一个索引。比如 name 和 age 组成一个索引

我们看到联合索引是按照 name,age 进行排序的,当 name 一样的时候,按 age 排序,并且叶子节点会有 id 的数据。
通过查询这个索引就可以得到对应数据行的数据主键,然后根据主键 id 查询聚簇索引得到整行数据。
# 覆盖索引
覆盖索引,也是联合索引。只是我们查询的数据就在索引中,不用再去 回表 查找数据了。
SELECT `name`,age FROM my_test WHERE `name` = b;
上述 sql 执行就利用了覆盖索引,查询的结果就在索引中。
SELECT * FROM my_test WHERE `name` = b;
索引中的数据只有 id,name,age,差 phone。这个数据只能通过回表去查询数据。
先查询 (name,age) 这个索引拿到主键 id,在通过主键 id 去聚簇索引中查询数据。
也有人经常推荐说,查询的时候要查询需要的字段,不要使用 select * ,这样做的好处一是减少 io,另一个就是避免回表。

# 索引的使用和添加
了解了 B+ 树索引数据结构,我们也就差不多知道怎样使用索引了,也可以理解使用索引的一些规则。
通常说的索引失效,一部分是可以从数据结构来推算出来的;另一部分就是 mysql 通过自身查询统计的数据判断不走索引性能会更高而导致索引失效而去全表扫描。
索引是为了我们从表中检索出少量数据才使用的。如果你添加了索引,当查询的时候还需要扫描表中绝大数的数据,就不用在这个字段添加索引了,因为这对你的查询没有任何提高,反而因为数据的修改需要维护索引,可能还降低了查询性能。
通常我们会选择区分度比较高的字段添加索引(如果这个字段和查询业务没有关系也没有必要添加索引)。
比如说性别这个字段,只有男、女两个选项,当你有 1000 w 的数据的时候,700w 是 男,300w 是女,就没必要添加索引了,没有意义。性别这个字段区分度较低。
SHOW INDEX FROM index_test;

当我们创建索引之后,可以通过查看 Cardinality 来判断索引添加是否合理。Cardinality/表总行数 值越接近 1 查询性能越好。
Cardinality 代表的是这个索引的数据唯一值的个数。现在表中有 5 行数据,并且 description 的值没有重复的。
数据库也会根据 Cardinality 进行优化查询,但这个值又不是实时更新的,我们需要每过一段时间,在业务不忙的时候更新这个值。
ANALYZE [NO_WRITE_TO_BINLOG | LOCAL] TABLE tbl_name [, tbl_name] ...
mysql> analyze table index_test;
+-----------------------+---------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+-----------------------+---------+----------+----------+
| index_blog.index_test | analyze | status | OK |
+-----------------------+---------+----------+----------+
1 row in set (0.00 sec)
# 最左匹配规则
我们在使用索引的时候,只需要包含索引的最左边就可以匹配索引(name,age)
SELECT * FROM my_test WHERE `name` = 'b';
SELECT * FROM my_test WHERE `name` = 'b' AND age = 1;
当我们执行下面的 sql 的时候,就用不到索引 (name,age)
-- 通过查看执行计划,看查询的性能:全表扫描
EXPLAIN SELECT * FROM my_test WHERE age=1;
最左匹配原则 是由 Mysql 的索引的数据结构决定的。
联合索引 (name,age) 的 B+Tree 数据结构中叶子节点是按照 name 排序再按照 age 排序。age 实际是乱序的,没有办法进行范围查找。
如果你还想在 age 进行索引查找,就需要在 age 上建立一个新索引。
-- 全表扫描
EXPLAIN SELECT * FROM my_test WHERE NAME LIKE '%a';
-- 索引范围查找
EXPLAIN SELECT * FROM my_test WHERE NAME LIKE 'a%';
索引的建立,不会整个字段值都参与索引的建立,一般会指定多长的字段(从值开头部分的长度)参与索引的建立。
当你需要关键字查找的时候,可以使用全文索引,或者是增加一个 ES 用于检索。
← Mysql 架构 Mysql 事务和锁 →